积分消耗机制指南
积分消耗机制指南
1. 积分消耗的基本单位:Token
积分的消耗是基于「Token」的概念来计算的。Token可以理解为文本中的单词、标点符号或字符片段(具体定义因模型而异)。无论是用户的输入还是 AI 的回应,所有的文本内容都会被分解为 Token,并根据这些 Token 的数量来计算积分消耗。

122个文字被拆分成85个Token(字数不等于Token数)
2. 价格系数:不同模型的消耗差异
不同的模型会有不同的「价格系数」。这个系数反映了模型的複杂度和运算成本。例如,一个高级模型可能具有更强大的语言理解和生成能力,但其模型系数也更高,因此每次互动的积分消耗也会相应增加。
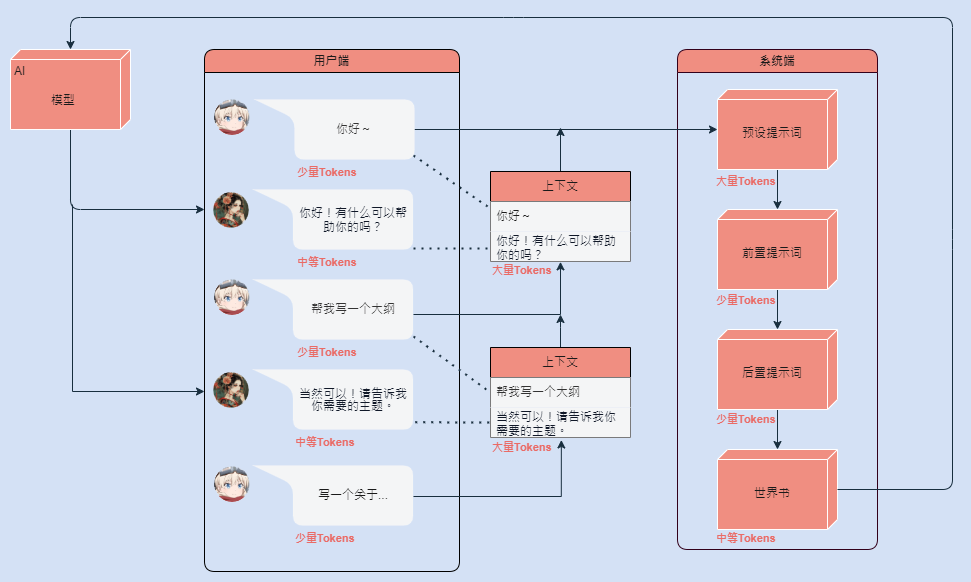
3. 积分消耗的组成部分
积分消耗主要由以下几个部分组成:
- 固定提示词(Prompt):为了确保作品能够按照预期的角色或风格回应,作者会设定一些固定的提示词。这些提示词在每次对话开始或重置时都会被使用,因此会产生一定的 Token 消耗。例如,如果作者设定了一些提示词来让 AI 扮演「专业客服」,这个提示词的 Token 数量将被计入每次对话的消耗中。
- 非固定提示词(世界书):非固定提示词是指放在世界书内的提示词,它们只会在接收到关键词才会启用。
- 用户输入:用户的每次输入(即问题或指令)也会被分解为 Token,并根据 Token 数量计算积分消耗。输入的长度越长,消耗的积分就越多。例如,输入「你好」消耗两个 Token,而输入一段长篇的描述则可能消耗数十甚至上百个 Token。
- AI 输出回应:回应的长度和複杂度直接影响积分消耗。
- 上文内容(上下文):为了确保对话的连贯性,系统会保留一定的对话历史(即上下文)。这些上文内容同样会被分解为 Token,并计入积分消耗中。上下文的长度通常受到「记忆大小」设定的限制,用户可以根据需要调整记忆大小,但记忆越大,积分消耗也越高。
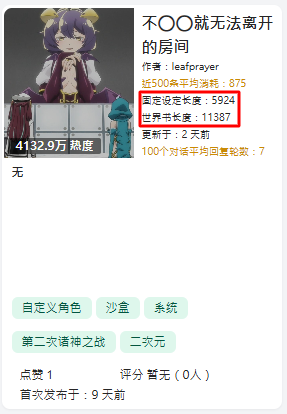
固定设定长度是指提示词的"字数",并非"Token数"
4. 计算与推算
积分消耗涉及模型系数的乘法计算,也可以通过除法逆向推算Token数。
正向计算(乘法)
积分消耗 = Token 数量 × 模型系数
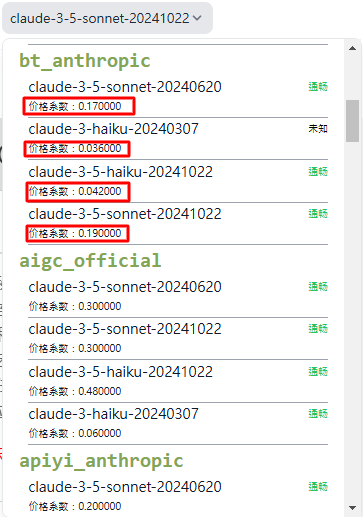
例如,yuegle的cladue系数为 0.12,总 Token 数为 1000,则积分消耗为:
\[ 1000 \times 0.12 = 120 \text{ 积分} \]
逆向推算(除法)
Token 数量 = 积分消耗 ÷ 模型系数
例如,若积分消耗为 200,模型系数为 0.042,则:
\[ \text{Token 数量} = \frac{200}{0.042} = 4761 \text{ Token} \]
记住消耗的Token包括:固定提示词、用户输入内容、AI输出内容(上文内容)。
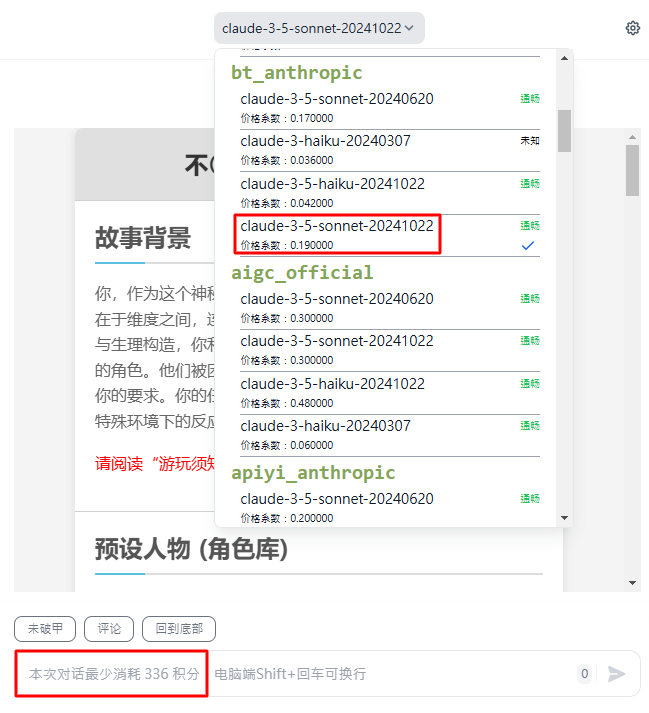
游玩新卡片前可以按照首次消耗来推算固定Token数,336/0.19=1768 Token
5. 减少积分消耗的方法
以下是针对积分消耗的减少方法,分别从作者(开发者或平台)和用户的角度提供建议:
对于作者
- 优化固定提示词:缩短提示词长度,使用简洁但有效的指令。例如,将「请以专业客服的口吻详细回答用户问题」简化为「专业客服回应」。避免重複或不必要的提示词,确保每次对话只使用必要的 Token。
- 使用世界书:如果你有一个複杂但又不太常用的的角色背景或世界设定,可以将其存入世界书中。
- 使用记忆区:记忆区用记录重要对话内容,将重要信息或关键点记录在记忆区中,这样可以使用户将记忆设定调低,大大减少在每次对话中需要消耗的Token。

用简洁的文字减少消耗 (181→134)
对于用户
- 选择低系数模型:阅读作者的简介,并使用推荐或低系数的模型,减少积分消耗。
- 调整记忆大小:如果对话不需要长篇上下文,将记忆大小设定为较低值,减少上文内容的 Token 消耗。
6. 工具
计算Token
https://tokencounter.org/claude_counter
优化提示词
https://aifuck.cc/explore/installed/fa69d490-d943-41e2-bc84-e8144a7a4f62