本文更新时间
写作于2025年1月6日,不保证本文内容能适配这个时间点之后的系统。
前置知识
模型看到了什么?什么是上下文?
模型指的是大语言模型,也就是AI,后面可能会用LLM的缩写。
创作界面中,把鼠标移动到“调试与预览”中AI回复的段落上,段落的右上角会出现“Prompt日志”的按钮,点击之后会弹出日志窗口,里面就是AI在响应这条消息时,所看到的内容。
我们后面会称之为上下文。
上下文的结构类似这样:
[系统:提示词]
[用户:主控指令n]
[助手:生成文段n]
[用户:主控指令n+1]
[助手:生成文段n+1]
[用户:主控指令n+2]
[助手:生成文段n+2]
...(循环)
模型的内在逻辑?
LLM可以简单理解为通过某种复杂机制预测文章接下来会出现某些字词的概率的机器。它有点像学校英语考试的完形填空选择题,有些时候你可能没什么读懂整个文章在说些什么,但看前后文字以及你对文章的大致理解,你通常还是能选出正确选项的。LLM干的是类似的事情。
它解读文本时有这样一些规则:
- 就像你做完形填空时,会优先考虑距离空位附近的文本那样,LLM生成文字时,也会优先考虑上下文中最下方的文字。越靠上权重越低、越靠下权重越高。
- 你不会只看附近的上下文,也会对文章整体做一些分析,LLM也是类似的。因此文章中明示的强调词(类似于注意、关键、高优先级等等),LLM会更注意一些。
- 如果文章首自然段是开门见山的点题和综述段落,你肯定会优先搞明白首段在说些什么对吧?LLM也是一样,LLM会优先考虑系统角色给出的提示词。
太长不看版本:AI会做完形填空,做完形填空时,它会优先参考:1、离空位(上下文最下方)最近的地方;2、语气强的词句;3、系统的提示词。
角色:
- 系统:LLM会提高系统提示词的参考权重
- 助手:LLM生成的内容(但其实你可以手改,LLM没有能力区分哪些是它自己生成的,哪些是你改的,哪些是你用其他AI生成的)
- 用户:你游玩时的身份
风月的机制:前置词、后置词、提示词都是什么?
简单来说,这些东西其实是“插入点”。
你的消息(上下文)在发送给LLM时,风月的系统会对上下文进行一些加工,在不同位置插入内容,拿我们之前的例子改造一下大概就是这样:
<上下文开始>
[系统:提示词,[(插入点:提示词),]]
[用户:主控指令n]
[助手:生成文段n]
[用户:主控指令n+1]
[助手:生成文段n+1]
...(循环)
[用户:[(插入点:前置词),]主控指令n+2[,(插入点:后置词)]]
[助手:生成文段n+2]
<上下文结束>
没错,你会发现...如果你插入的提示词、前置词、后置词有多条,风月会给你补充逗号……
风月的系统里,你可能会在各种地方看到前置词、后置词、提示词,有的是用户侧、有的是在创作者侧,实际上指的都是一个东西:在上下文中插入定制内容的位置。
所以,你写作品时,最关键的其实是“提示词”部分,因为提示词在上下文中是系统角色给出的,LLM设计上对系统角色的内容有高权重。
世界书
世界书是什么?
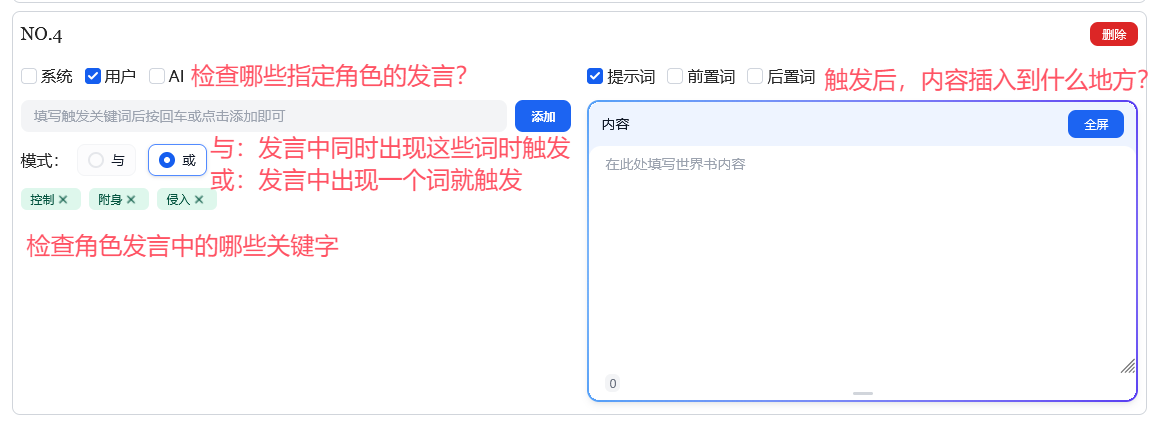
世界书是一种条件触发的、在上下文中插入内容的机制,它模拟了类似于百科/知识库的功能。
风月的系统会检索上下文全文,当指定角色的发言中,有指定的词或词语组合时,在指定位置插入内容。
如下:
为什么会有世界书这种系统?
这就涉及到LLM的计费方式和运行逻辑了。
之前提到过,LLM会根据上下文进行“完形填空”,那么上下文越长,“完形填空”的难度也就越大,于是指定平台的计费也就越高。
通常LLM计费是分成输入和输出两部分的,按文字量计费。输入就是提交给LLM的上下文,输出就是LLM输出的文段。输入的计费通常会低一些,输出的通常会高一些。
然后,有些平台会有缓存,输入的上下文命中缓存时,计费会更少一些。
世界书这种机制就允许你把自己的设定拆散,然后根据需要进行组合,放进上下文里。以减少输入的长度、节约费用。
另一方面,有些时候,当上下文过长时,LLM对系统指令(提示词)的注意力会下降,这种之后,反而是最近一条的用户指令效力更高(前置词、后置词)。因此,世界书还有调节作品指令系统的功能。